Table of Contents
Web crawlers, or “spiders,” help search engines discover and index websites. Learn about different types of crawlers and how they work.
What Is a Web Crawler?

Web crawlers are like special programs that automatically visit websites, read their content, and tell search engines about them. This helps search engines know what information is on the web and show it to people searching for it.
These crawlers are like tireless explorers, travelling across the web and following links to discover new information. They work behind the scenes to keep search engines up-to-date and help you find what you’re looking for online.
How Do Web Crawlers Work?
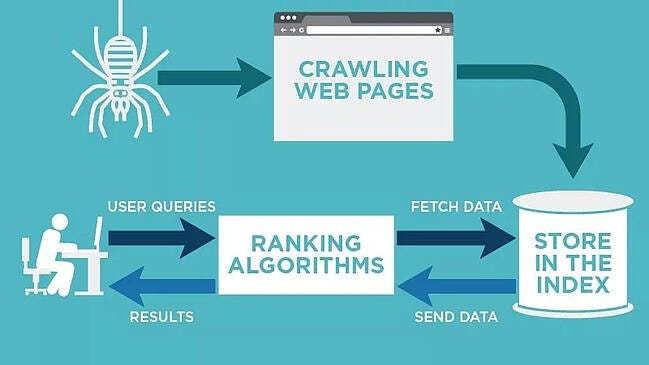
Web crawlers, also known as spiders or bots, are automated programs that constantly scan and index web pages for search engines. Here’s a breakdown of their process:
1. Starting point
Crawlers begin with known web pages, like popular websites or those with many links pointing to them.
2. Following links
They follow links on these pages, discovering new websites and adding them to their list. This process works similarly to how you might click on links while browsing the internet.
3. Reading and understanding
Once on a new page, the crawler reads the content and tries to understand the information it contains. This might involve analyzing the text, images, and other elements on the page.
4. Storing information
The crawler stores the gathered information in a massive database maintained by the search engine. This database is called an index.
5. User searches
When you enter a search query, the search engine retrieves relevant web pages from the index based on your keywords and other factors. This is why search results often appear almost instantly.
6. Controlling access
As a website owner, you can control which crawlers access your site using a robots.txt file. This file tells crawlers which pages they can and cannot scan and index.
By understanding how web crawlers work, you can help them discover your website and make it more visible in search engine results.
Different Types Of Web Crawlers
As you build your crawler list, it’s important to be aware of the different types available, each serving distinct purposes:
1. In-house Crawlers
Imagine a company having its team of scouts checking its website. These in-house crawlers are custom-built programs designed to explore and analyze the company’s website specifically. They’re often used for tasks like website health checks and content optimization.
2. Commercial Crawlers
Think of these as specialized tools, like powerful microscopes, that companies can purchase. Commercial crawlers, like Screaming Frog, are built with specific functionalities to deeply analyze and evaluate website content efficiently.
3. Open-Source Crawlers
Imagine a community project where anyone can contribute and use the tools. Open-source crawlers are freely available and developed by various programmers around the world. They offer a good starting point for those who want to explore website crawling without initial investment.
Understanding these different types of crawlers empowers you to choose the right ones that align with your business goals and resource constraints.
Web Crawler List: Most Common Ones In 2024
The vast world of the internet is constantly explored by tiny programs called web crawlers, also known as spiders or bots. These crawlers are sent by search engines to discover and index websites, making them searchable for users. Let’s meet some of the most common web crawlers:

1. Googlebot
The most well-known crawler, working for Google search. It scans websites to keep Google’s search results up-to-date. There are different versions of Googlebot for different devices, like desktops and smartphones.
Websites can control how Googlebot interacts with them through a file called robots.txt.
Google stores information about scanned pages in a database.
2. Bingbot
Microsoft’s Bing search engine uses Bingbot to gather information and ensure relevant search results for its users.
Bingbot, created by Microsoft in 2010, is a web crawler used by the Bing search engine to visit websites and gather information about their content and structure.
3. Yandex Bot
Yandex Bot, also known as Yandex Spider, is a web crawler specifically designed for the Russian search engine Yandex.
Crawls and indexes web pages for Yandex Search. Primarily focuses on websites relevant to the Russian market.
Website owners can control how Yandex Bot interacts with their site through several methods:
- robots.txt file: This file allows website owners to specify which parts of their site Yandex Bot can access.
- Yandex.Metrica tag: Adding this tag to specific pages can help Yandex Bot discover them more easily.
- Yandex Webmaster tools: These tools provide website owners with various options to manage how their site is indexed by Yandex, including submitting new or updated pages.
- IndexNow protocol: This protocol allows website owners to quickly inform Yandex about changes made to their website.
By understanding how Yandex Bot works, website owners can optimize their websites for better visibility in Yandex search results, specifically for users in the Russian market.
4. Applebot
Apple’s Siri and Spotlight features rely on Applebot to crawl and index webpages, helping users find what they’re looking for on their Apple devices.
5. DuckDuck Bot
Focused on privacy, DuckDuckGo uses DuckDuckBot to crawl the web while protecting user privacy.
6. Baidu Spider & 7. Sogou Spider
These two crawlers power Baidu and Sogou, leading search engines in China, ensuring relevant search results for users in that region.
8. Facebook External Hit
This crawler helps Facebook understand the content of websites shared on the platform, allowing for better previews when links are shared.
9. Exabot
Crawling for Exalead, a search platform company, Exabot helps them rank search results based on website content and backlinks.
10. Swiftbot
This crawler is a bit different. It belongs to Swiftype, a company offering custom search solutions for websites. Swiftbot only crawls websites specifically requested by its customers.
11. Slurp Bot
This familiar name belongs to Yahoo’s search engine crawler. Slurp Bot helps Yahoo gather information and personalize search results for its users.
12. CCBot
Working for a non-profit organization called Common Crawl, CCBot gathers and shares internet data for research and development purposes.
13. GoogleOther
A newcomer launched by Google in 2023, GoogleOther shares the same features as Googlebot but helps manage Google’s crawling workload internally.
14. Google-InspectionTool
This new crawler assists with testing and inspection tools within Google Search Console and other Google properties.
By understanding these different crawlers, you can gain valuable insights into how search engines discover and index your website.
Final Thoughts
Web crawlers, also known as spiders or bots, are programs that automatically visit websites and gather information for search engines. This helps search engines understand the web and display relevant results to users.
There are different types of crawlers, each serving specific purposes. Some common crawlers include Googlebot, Bingbot, and Yandex Bot. By understanding how crawlers work, website owners can optimize their websites for better search engine visibility.
For More Information Please Visit These Websites Craiyon And Arturia